
One of the many powerful features of the Oracle Database is the Automatic Workload Repository report or short AWR report. The Automatic Workload Repository (AWR) continuously collects performance statistics from the Oracle Database. AWR reports can then be generated which summarize all database activity between two timestamps. These reports help readers detect performance issues and/or fine-tune a database for optimal workload performance.
This feature is so powerful and advanced compared to any other database that it is part of the commercial Oracle Diagnostics Pack, an extra cost option for Oracle Database Enterprise Edition. However, users of Oracle Database Free can freely use AWR for educational purposes (remember, Oracle Database Free is resource-constrained, so performance bottleneck detection makes little sense on Oracle Database Free).
Getting an AWR Report
Generating an AWR Report usually consists of three steps:
- Create the begin snapshot (periodic snapshots are automatically taken)
- Create the end snapshot (periodic snapshots are automatically taken)
- Generate a report within the two snapshots
To do so, one would usually use the DBMS_WORKLOAD_REPOSITORY PL/SQL package by calling the CREATE_SNAPSHOT() and the AWR_REPORT_HTML() functions respectively.
However, people who have done this in the past know that the AWR_REPORT_HTML() function requires additional information, such as the database identifier (dbid) and the instance number. And that is still not enough, the generated HTML output needs to be spooled into a file, but ideally without a page size and line sizes, so that the HTML remains valid.
Wouldn’t it be nice if there was a quicker, easier and fool-proof way of generating an AWR report, ideally directly from the command line? That is what I thought to myself a while back and so I decided to dig out my Java developer skills again and added a new awr command to SQLcl which makes generating AWR reports a breeze.
Generating an AWR Report with SQLcl
Inside SQLcl, you now have a new awr command at your disposal. This one command combines three capabilities:
- Creating snapshots
- Listing snapshots
- Creating AWR reports
Furthermore, it is intelligent enough to discover the dbid and instance id by itself and uses the second last and last snapshots by default. You need to be connected with a user who has execution privileges on DBMS_WORKLOAD_REPOSITORY and SELECT privileges on the underlying views. Usually, the SYSTEM user will do, but of course, any other user with the right privileges can be used as well. Let’s take a look.
SQLcl awr general syntax
If you just type awr you will be presented with the following syntax diagram:
SQL> awr
Missing token at character AWR
Creates and retrieves AWR reports for the currently connected instance.
Usage:
awr <create_snapshot> | <create_report> | <list_snapshots>
<create_snapshot> := create snap[shot] (bestfit | lite | typical | all)?
<create_report> := create (html | text)? <begin-snapshot-id>? <end-snapshot-id>?
<list_snapshots> := list snap[shots]
<create_snapshot>
Creates a new snapshot and prints its id.
The optional parameter flush-level of the snapshot are (BESTFIT, LITE, TYPICAL, ALL).
<create_report>
Creates a new AWR report and writes it to a file called "AWR-<DB_Name>-<PDB_Name>-<Current Timestamp>.[html|txt]" in the current working directory.
<begin-snapshot-id>
Beginning snapshot id for the AWR report.
By default, the second last snapshot id is taken if no id has been provided.
<end-snapshot-id>
Ending snapshot id for the AWR report.
By default, the last snapshot id is taken if no id has been provided.
<list_snapshots>
Lists the available snapshots in the database.
More help topics:
AWR EXAMPLES
AWR SYNTAX
SQL>
The most important part of this is the first line under “Usage”:
awr <create_snapshot> | <create_report> | <list_snapshots>
This tells you that awr has three subcommands: <create_snapshot>, <create_report>, <list_snapshots>
The next lines give you the options of the subcommands.
<create_snapshot> := create snap[shot] (bestfit | lite | typical | all)?
This means that you can type awr create snap[shot] [bestfit | lite | typical | all] to create a snapshot. The characters “shot” are optional and so is the snapshot flush level which translates directly to the flush_level parameter of DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT().
<create_report> := create (html | text)? <begin-snapshot-id>? <end-snapshot-id>?
This means that you can type awr create [begin-snapshot-id] [end-snapshot-id] to create a report. The report type of html (default) or text is optional and so are the begin snapshot id (default: second last snapshot id) and end snapshots id (default: last snapshot id)
<list_snapshots> := list snap[shots]
This means that you can type awr list snap[shots] to list all existing snapshots in the system. The characters “shots” are optional.
Creating snapshots
To create one or more snapshots, just type awr create snap. By default, the flush level is NULL, which means the default from CREATE_SNAPSHOT() is taken (which is 'BESTFIT'). You will also notice that the snapshot ID of the newly created snapshot is returned:
SQL> awr create snap
Snapshot taken, ID: 2
To use a different flush level, just add it as an additional parameter:
SQL> awr create snap all
Snapshot taken, ID: 3
Of course, feel free to type out the word “snapshot”:
SQL> awr create snapshot typical
Snapshot taken, ID: 4
Listing snapshots
To list all the available snapshots, just type awr list snap. Internally, the view dba_hist_snapshot is queried:
SQL> awr list snap
SNAP_ID DBID BEGIN_INTERVAL_TIME END_INTERVAL_TIME
__________ ____________ __________________________________ __________________________________
1 180333692 04-APR-25 02.18.37.167000000 PM 04-APR-25 02.29.36.337000000 PM
2 180333692 04-APR-25 02.29.36.337000000 PM 04-APR-25 02.42.17.549000000 PM
3 180333692 04-APR-25 02.42.17.549000000 PM 04-APR-25 02.46.22.711000000 PM
4 180333692 04-APR-25 02.46.22.711000000 PM 04-APR-25 02.47.11.935000000 PM
SQL>
Creating AWR reports
To create an AWR report, just type awr create. Here are the thoughts that I put into this. During my usual performance tuning exercises, I always take a snapshot just before the test workload and immediately afterward and then create a report from the two. I rarely recall scenarios where I generated AWR reports that weren’t from the last two snapshots. Hence, I wanted to make AWR generation as quick and easy as possible. awr create snap, awr create snap, awr create and that’s it (you may also notice the carefully picked awr create ... grammar). Of course, there are other scenarios. Hence, snapshot ids, report type and snapshot flush level can all be provided. But the default should be kept as simple as possible, so simple in fact, that you don’t even have to specify where the report will be written to. It will be put in the current working directory from which you invoked SQLcl. The file name will be awr_<PDB|CDB name>_<begin-snapshot-time>_<end-snapshot-time>.<html|txt>
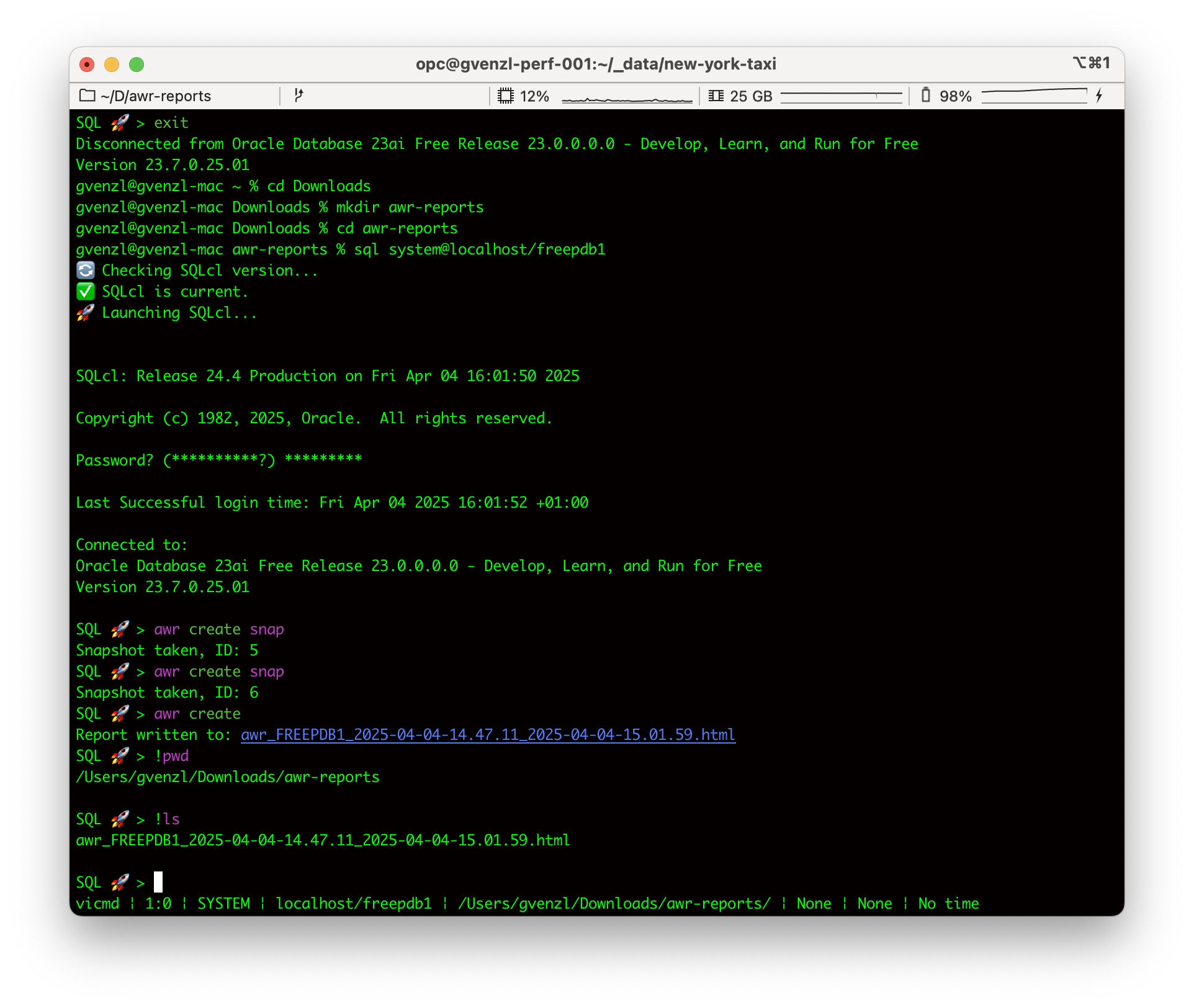
So, for example, to create said report, I can do the following:
SQL> awr create snap
Snapshot taken, ID: 5
SQL> awr create snap
Snapshot taken, ID: 6
SQL> awr create
Report written to: awr_FREEPDB1_2025-04-04-14.47.11_2025-04-04-15.01.59.html
SQL>
In my case, I invoked SQLcl from the directory /Users/gvenzl/Downloads/awr-reports:
SQL> !pwd
/Users/gvenzl/Downloads/awr-reports
SQL>
And this is where I can find the report:
SQL> !ls
awr_FREEPDB1_2025-04-04-14.47.11_2025-04-04-15.01.59.html
SQL>
On Mac, you can even immediately open the file in your browser by holding the [Cmd] key and hovering over the file name, which will turn into a clickable link:
I hope you find this new command as useful as I do. I have since never looked back at exec DBMS_WORKLOAD_REPOSITORY...